Web Superficial y Web "Profunda"

Web Superficial.
Cuando hablamos de la web superficial, nos referimos a todo el conjunto de sitios web que pueden ser indexados por los búscadores convencionales como google, bing, yahoo entre otros, mediante una simple petición en los formularios de búsqueda por parte del usuario.
Sus caracteristicas principales son las siguientes:
- Su información no se encuentra en bases de datos.
- Cualquier persona puede acceder a ella.
- Por lo general, son páginas web estaticas es decir, que tienen una url fija.
Estas caracteristicas son las que permiten a los buscadores encontrarlas facilmente.
Web Profunda.
Es el termino utilizado para referirse a la páginas que no estan catalogadas en los buscadores comunes, debido a que tienen ciertas caracteristicas tecnicas que no permiten o más bien, dificultan la tarea que tienen los buscadores para indexarla.
"El término Web invisible (invisible Web) fue introducido a mediados de los años 90 por Jill Ellsworth y Matthew Koll y popularizado por Intelliseek en 1998 mediante el servicio invisibleweb.com"
Veamos pues cuales son:
- Información generalmente contenida y accesible mediante bases de datos.
- URLs dinamicas que se realizan por parte del usuario. (ASP, PHP, etc)
- No son de libre acceso (Login requerido).
Este grafico nos muestra la pequeña cantidad que puede ser indexada por los buscadores y la otra parte que queda oculta, la llamada web invisible.
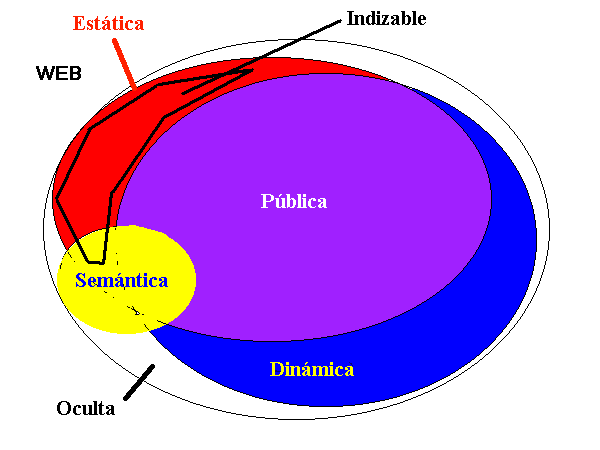
Fuente: Ricardo Baeza Yates. http://www.dcc.uchile.cl/~rbaeza/inf/webfaces.gif
Sherman y Price identifican cuatro tipos de contenido de la web invisible.
Web opaca (theopaque Web), la Web privada (the private Web), la Web propietaria (the proprietary Web) y la Web realmente invisible (the truly invisible Web).
La web opaca
Esta compuesta por páginas que podriamos encontrar en los buscadores pero una parte de ella no.
Por los siguiente motivos.
- Por economia los buscadores no indizan todo el sitio web.
- Los buscadores limitan el numero de resultados por lo general entre 200 y 1000.
- URLs desconectadas, es decir que en su contenido no hay ninguna referencia a otro sitio web o página.
Web Privada.
Los propietarios del sitio web aplican algunos parametros a sus sitios que impiden que los buscadores puedan indexarlos facilmente.
- Información solo para usuarios registrados
- Archivos como robot.txt y noindex.txt evitan que los buscadores puedan encontrarlas.
Generalmente solo se puede acceder a ella mediante un registro previo aunque sea gratuito.
Web Realmente Invisible
Son sitios generados dinamicamente es decir que se muestran solo por petición del usuario, no por un buscador. Además cuentan con limitaciones tecnicas para los buscadores dificultando su tarea.
Según LLuis Codina el termino invisible no es adecuado para referirse a este tipo de sitios web que no pueden ser encontrados por los buscadores el prefiere llamarlos no indizable. Del mismo modo estoy de acuerdo con este autor ya que este tipo de webs en algun momento llegaran a ser indizables por los buscadores, solo es cuestion de tiempo de que se mejore la tecnologia u otras personas permitan que su información sea más accesible.
Otro de los puntos que me gustaria hacer referencia y que no se encuentran en las guias del curso son las llamas páginas de la Deep Web o web profunda que son sitios encriptados mediante la dirección .onion que no son accesibles mediante un navegador convencional y mucho menos por un buscador.
Para ello hace falta hacer uso del navegador TOR que permite acceder a ellas.
Entorno a este tipo de web hay una gran cantidad de información.
- Silk Road
- Los proyectos The Onion Router, (Tor), ideado en sus orígenes por el U.S. Naval Research Laboratory, software libre cuyo objetivo principal es el desarrollo de una red de comunicaciones distribuida de baja latencia y sobrepuesta a la red internet en la que no se revela la dirección IP, es decir, la identidad de sus usuarios, manteniendo además la integridad y la ocultación de la información que transita por ella, (existe la versión para móvil denominada Orbot) y The Freenet Project de características similares.
- El sistema operativo Tails, cuyo objetivo es la preservación de su intimidad y el anonimato como el buscadorDuckduckgo.
- Shodan, buscador especializado en la localización de vulnerabilidades en la red relacionadas con las organizaciones.
- Los programas de software libre para redes P2P descentralizadas como GNUnet o la japonesa Perfect Dark(P2P).













![Hombre VS Canguro | Final Inesperado [Recomendado]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_sHRALZv-Egu830azxWBmQ8-RB-V7DJkQS0_V9Ck7G4yfEvMvqiKoQJ9mWC4ixncTzkqZF54ruiimjAqsBU6nVWNbsuZYCKBFqS0wy3OgZrofQ)

0 comentarios: